DALL-E는 입력으로 받은 텍스트의 개념을 이미지로 생성하는 모델입니다. 아래와 같이 현실 세계에 존재하지 않을 법한 이미지도 텍스트의 묘사와 유사하게, 고품질로 생성하여 많은 주목을 받았습니다.

DALL·E: Creating Images from Text
We’ve trained a neural network called DALL·E that creates images from text captions for a wide range of concepts expressible in natural language.
openai.com
본 포스트에서는 DALL-E의 핵심 구성요소 중 하나인 VQ-VAE에 대하여 설명합니다. VQ-VAE 논문과 특히 https://ml.berkeley.edu/blog/posts/vq-vae/ 포스트를 참고하였습니다.
Motivation
VAE는 Autoencoder로 데이터의 latent space를 찾으면서, 동시에 variational inference를 통해 latent space를 normal distribution을 가정한 prior로 regularization 합니다. Autoencoder로 학습한 latent space는 continuous vector space가 되는데, continuous 이어야 할 필요가 있을까요?
사실 현실 세계에 많은 데이터는 discrete 합니다. 아래 이미지로 예를 들어보죠. Object는 고양이, 고양이가 앉아 있는 곳은 벤치, 배경 색은 갈색, 배경의 texture ..

또한, transformer와 같이 discrete data에 동작하도록 디자인된 알고리즘들이 많습니다. 이와 같은 이유로 discrete latent representation은 유용해 보입니다. VQ-VAE는 vector quantization이라는 기법으로 latent space를 discrete 하게 만듭니다.
Vector Quantization
VQ-VAE는 Autoencoder 구조에 discrete 한 codebook을 더했습니다. Codebook은 기본적으로 벡터를 요소로 가지는 리스트입니다. Encoder의 출력으로 어떤 벡터가 나오면, codebook의 모든 벡터들 간 거리를 계산합니다. Codebook의 벡터들 중 encoder의 출력 벡터와 가장 거리가 짧은 벡터를 찾습니다. 그리고 그 벡터를 decoder에 넣어 학습합니다.

위 이미지는 VQ-VAE의 구조와 동작 예시입니다. 강아지를 encoder에 넣어 벡터 z_e(x)가 출력되었습니다. z_e(x)와 codebook의 벡터들 e_1, e_2,..., e_k 간 거리를 계산해본 결과 e_2가 가장 가깝습니다. z_e(x) 대신 e_2를 decoder의 입력으로 넣어 학습합니다.
Codebook 안의 벡터들의 개수가 제한되면 다양한 이미지를 생성하는 것이 가능할지 의문이 들 수 있습니다. 사실 일반적으로 encoder의 출력은 하나의 벡터가 아닙니다. 예를 들어 이미지를 학습하는 경우 32x32X1 벡터가 출력되도록 encoder를 디자인할 수 있습니다. 그럼 각 grid는 codebook의 벡터들 중 가장 가까운 벡터로 변환될 것이고, 만약 codebook list의 크기가 512라면 512^(32*32) 만큼의 distinct 한 이미지들을 생성할 수 있게 됩니다. 32x32 feature map의 각 요소 값은 가장 가까운 벡터의 index로 replace 되므로, discrete 한 vector space를 얻었다고 할 수 있습니다.

VQ-VQE의 loss function은 세 term으로 구성됩니다:
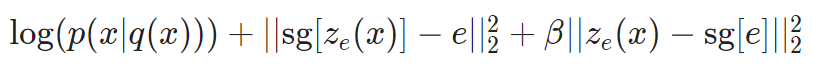
첫 번째 항은 reconstruction loss, 두 번째 항은 codebook alignment loss, 그리고 세 번째 항은 codebook commitment loss입니다. sg는 해당 term에는 weight가 업데이트되지 않는 "stop gradient"를 의미합니다. Codebook alignment loss는 encoder의 출력인 z_e(x)와 가장 가까운 codebook 내 vector e_i가 z_e(x)와 더 가까워지도록 합니다. Codebook commitment loss는 그 반대입니다.

Learning priors
VQ-VAE를 학습하는 과정에서는 prior를 uniform distribution으로 둡니다. VQ-VAE로 discrete 한 latent space를 얻어 학습이 종료되면, prior를 autoregressive model를 활용하여 latent space와 닮아가도록 learning 할 수 있습니다. Learning prior와 discrete latent space를 활용하여 새로운 음악을 만들거나 text to image 모델을 만들 수 있게 됩니다.
참고
1. Van Den Oord, Aaron, and Oriol Vinyals. "Neural discrete representation learning." Advances in neural information processing systems 30 (2017).