Liu, Yang. "Fine-tune BERT for extractive summarization." arXiv preprint arXiv:1903.10318 (2019).
모델 소개 및 구조 설명
BERT를 extractive summarization에 맞게 fine-tune한 논문입니다. BERTSUM이라는 이름으로 통용되는 모델입니다.
Summarization task는 abstractive, extractive summarization으로 나뉩니다. Abstractive summarization은 새로운 문장들을 생성하여 요약하는 방법이고, extractive summarization은 전체 문장에서 요약문에 포함될 문장들을 선택하여 요약하는 방법입니다. 다시 말해, m개의 문장을 포함하는 document d를 [sent_1, sent_2, ... , sent_m] 와 같이 표현하면, 각 sent_i에 0 혹은 1의 label을 부여하는 일입니다. 1의 label이 부여된 문장들만 요약문에 포함됩니다.
BERT를 extractive summarization task에 fine-tune하기 위하여 1) input에 대한 약간의 수정 2) summarization layers 추가 와 같은 두 가지 개선이 있었습니다.
1. input에 대한 약간의 수정
BERT에서는 입력 문장을 WordPiece 로 tokenize하고, sequence의 시작에는 [CLS] 토큰과 sentence간 구분에는 [SEP] 토큰이 사용됩니다.
1) Tokenizer
문장을 BERT에 입력하여 embedding하기 전에, 의미를 가지는 단어 혹은 글자들로 tokenize하고 컴퓨터가 이해할 수 있는 숫자로 변형해주는 작업이 필요합니다. WordPiece는 문장을 글자들로 tokenize하고, 이를 WordPiece가 가지고 있는 index들로 변형하여 return해주는 subword tokenizer입니다. 예를 들어 '경찰차'와 같은 단어가 있으면, 이를 '경찰' 그리고 '차'로 나눠줍니다. 그리고 WordPiece가 가지고 있는 사전에 '경찰'이 1421 index에, '차'가 581 index에 적혀 있으면 1421 581을 return합니다.

2) [CLS], [SEP] token
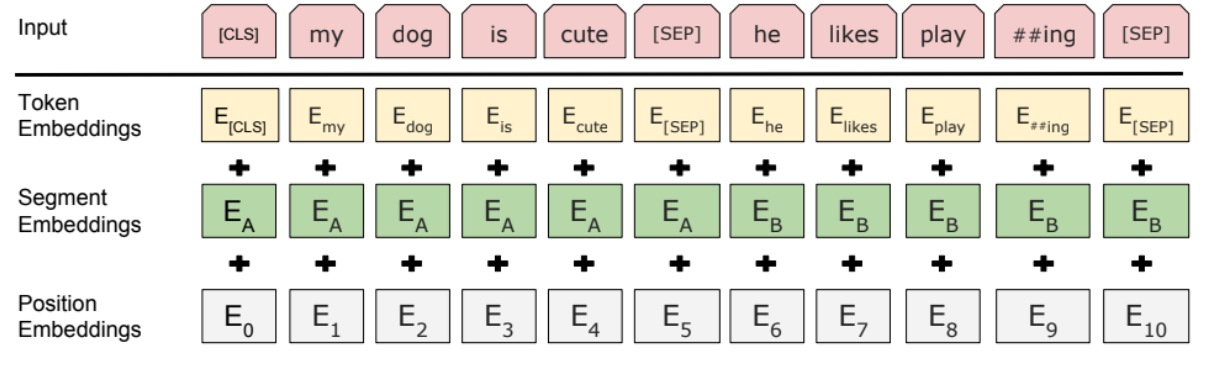
BERT는 MLM과 NSP를 통해 Semi-supervised learning을 합니다. 즉 한 문장이 입력되거나 두 문장이 입력될 수 있습니다. 두 문장이 입력된 경우 문장 간의 구분이 필요한데, 이를 [SEP] 토큰이 하게 됩니다.
BERT에서는 한번에 입력되는 문장들을 sequence라고 부릅니다. [CLS] 토큰은 classification 를 위한 토큰입니다. BERT encoder는 hidden states의 sequence를 출력으로 보내는데, classification task를 위해서는 하나의 vector로 reduced 되어야 합니다. 이를 위해 BERT에서는 first token인 [CLS] 토큰의 hidden state을 사용니다.

3) Segment Embeddings
BERT에서는 하나 혹은 두 문장이 입력됩니다. 따라서 모델은 입력 토큰들이 각각 어떤 문장에 속하는지 알아야 합니다. 이를 위해 segment embedding이 활용됩니다. 알고리즘은 간단한데, 각 토큰이 첫 번째 문장에 속하면 0을 두 번째 문장에 속하면 1을 부여합니다.

BERTSUM의 input embedding은 BERT와 거의 유사입니다. 다만 BERTSUM에서는 여러 문장이 입력될 수 있기 때문에, 1) 문장 앞 뒤로 [CLS]와 [SEG] 토큰이 붙는다는 점과 2) segment embedding이 이어진 문장을 구분하기 위하여 홀수번째 문장에 속한 토큰은 0, 짝수번째 문장에 속한 토큰은 1이 붙습니다.

2. Summarization layers 추가
Summarization task를 수행하기 위하여 BERT 위에 summarization layer들을 얹습니다. 여러 문장(sent_i)이 BERT에 입력 되면 각 문장의 embedding vector(T_i)가 출력됩니다. 이 embedding vector(T_i)를 summarization layers에 넣으면 각 문장의 요약문에 포함될 확률인 Y_i를 얻을 수 있습니다.
Summarization layers로 1) fully connected layer로 구성된 simple classifier, 2) transformer layer를 두 개 얹은 inter-sentence transformer 3) LSTM을 얹은 classifier를 실험하였고, inter-sentence transformer를 활용한 경우가 가장 성능이 좋았습니다. 이에 대해 조금 더 자세히 적어보겠습니다.
Inter-sentence transformer
Embedding vectors T에 먼저 positional embedding을 더 합니다. Positional embedding은 sin과 cos을 활용하여 입력된 index를 표현하는 embedding vector입니다. 같은 단어라도 그 단어가 쓰여진 위치에 따라 조금씩 달라집니다. 따라서 semantic을 표현하는 T에 positional embedding을 더해지게 되면 더 정교한 semantic을 표현한다고 이해할 수 있습니다. Positional embedding이 더해진 후, tansformer layer가 2개와 하나의 fully connected layer가 쌓입니다.

Transformer 내 MultiHeadAttention과 Positional Feed Forward의 입력을 다시 add하는 부분이 있는데, ResNet[2]의 아이디어를 활용한 것으로 생각됩니다. Layer가 깊어질수록 gradient vanishing/exploding 현상이 발생하여 적절한 수의 layer를 쌓는 것이 중요한데, ResNet에서는 전 layer의 입력을 그대로 더해주는 skip-connection 을 활용합니다. 그럼으로서 loss를 개선하는데 layer가 필요가 없으면 residual이 업데이트 되지 않아, layer 수를 자동으로 최적화하게 됩니다.

실험 결과
BERTSUM에서는 top-3 문장을 trigram blocking을 적용하여 요약문에 포함하였습니다. trigarm blocking은 이미 요약문으로 선택된 문장과 후보 문장 간 겹치는 trigram(a group of three consecutive written units such as letters, syllables, or words.)이 있다면 후보 문장을 제외하는 방식입니다.
BERTSUM에서는 두 벤치마크 데이터 셋인 CNN/DailyMail news highlights dataset 과 the New York Times Annotated Corpus 으로 실험하였습니다. CNN/DailyMail 은 뉴스 기사와 이에 대한 간단한 overview를 포함합니다.
{'id': '0054d6d30dbcad772e20b22771153a2a9cbeaf62',
'article': '(CNN) -- An American woman died aboard a cruise ship that docked at Rio de Janeiro on Tuesday, the same ship on which 86 passengers previously fell ill, according to the state-run Brazilian news agency, Agencia Brasil. The American tourist died aboard the MS Veendam, owned by cruise operator Holland America. Federal Police told Agencia Brasil that forensic doctors were investigating her death. The ship's doctors told police that the woman was elderly and suffered from diabetes and hypertension, according the agency. The other passengers came down with diarrhea prior to her death during an earlier part of the trip, the ship's doctors said. The Veendam left New York 36 days ago for a South America tour.'
'highlights': 'The elderly woman suffered from diabetes and hypertension, ship's doctors say .\nPreviously, 86 passengers had fallen ill on the ship, Agencia Brasil says .'}
Hermann et al. [1]에서 제한한 것과 같이, training, validation, 그리고 testing (90,266/1,220/1,093)으로 CNN documents를, 196,961/12,148/10,397으로 DailyMail documents를 나누었습니다.

Interval segments와 trigram blocking의 성능을 평가하기 위하여 ablation study를 진행하였습니다. Table2는 그 결과 인데, 특히 trigram blocking이 성능 향상에 기여하는 부분이 많음을 확인할 수 있었습니다.

논문을 읽고 궁금한 점
- BERTSUM에서는 X로 문서 내 모든 문장을 입력하고 Y로 각 문장이 summary에 포함될 확률을 출력합니다. 따라서 훈련할 때 CNN/dailymail 데이터 셋도 이와 같은 형태로 바꿔주어야 하는데 highlights를 활용하여 각 문장의 Y를 구하는 방식에 대하여 나와 있지 않습니다. 구글링 해본 결과 1) 각 문장과 true summary 를 embedding vector로 변환하여 cosine similarity를 구하거나, 2) 각 문장과 true summary 간 ROUGE를 계산하는 방식이 있을 것 같습니다.
References
[1] Karl Moritz Hermann, Tomas Kocisky, Edward Grefenstette, Lasse Espeholt, Will Kay, Mustafa Su-
leyman, and Phil Blunsom. 2015. Teaching machines to read and comprehend. In Advances in Neural Information Processing Systems, pages 1693–1701.
[2] He, Kaiming, et al. "Deep residual learning for image recognition." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.