Jia, Ruipeng, et al. "Neural extractive summarization with hierarchical attentive heterogeneous graph network." Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020.
Extractive summarization의 최신 연구들은 gold summary와 높은 semantic similarity를 가지면서 선택된 문장들 간의 redundancy를 줄이는데 집중되어 있습니다. 하지만 문장들 간의 dependency를 정확히 모델링하는 것은 여전히 어렵습니다.
본 논문에서는 단어와 문장들을 포함한 정보들을 모델링하고 문장들 간 의존 관계에 집중하는 HAHSum(Hierarchical Attentive Heterogeneouse Graph for Text Summarization) 모델을 제안합니다. HAHSum의 접근 방식은 반복적으로 문장의 representation을 redundancy-aware graph로 정제하고, message passing을 통해 label dependencies를 전달합니다. Benchmark corpus에 실험한 결과 이전 extractive summarizer을 outperform 하는 성능을 보였습니다.

Methodology
- 방법론 요약
- ALBERT로 단어, 문장 임베딩을 출력
- 단어-단어, 단어-문장, 문장-문장을 그래프로 모델링
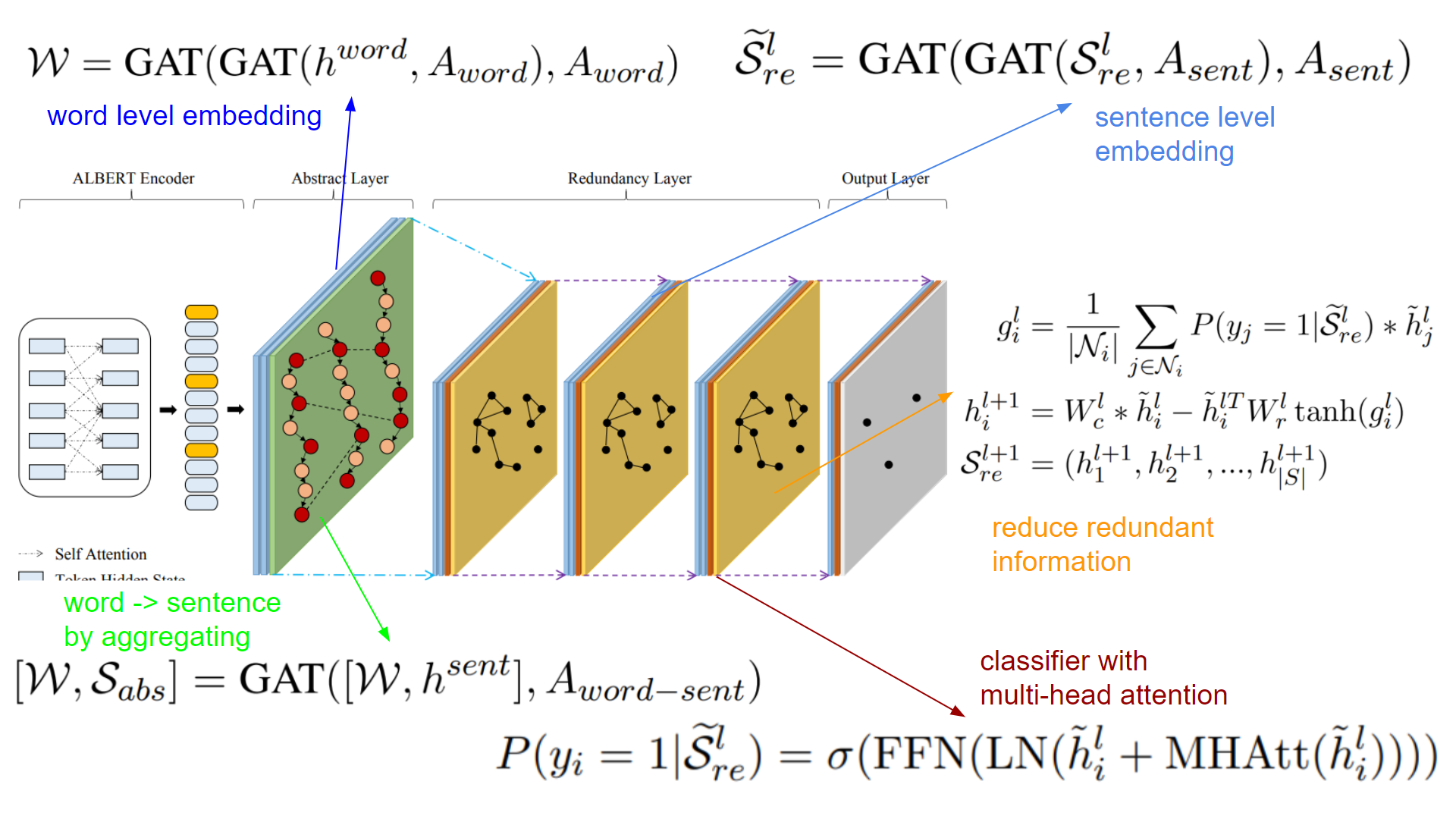
- Abstract Layer에서 GAT로 각 단어의 semantic representation을 학습하고, 각 word가 속해 있는 sentence node로 aggregating하여 word-level graph를 sentence-level graph로 전환
- Redundancy Layer에서 문장 임베딩에 그 문장과 유사한 문장들의 임베딩을 빼서 redundancy를 줄임
- Output Layer에서 classifier로 각 문장의 label 예측
- Problem Definition
S = {s_1, s_2, ..., s_N} 은 N개의 문장을 가지고 있는 document sequence를 의미합니다. 그리고 s_i는 문서의 i번째 문장을 의미합니다. T는 gold summary (정답 요약)을 의미합니다. T로부터 s_i가 extractive summary에 포함될지 결정하는 Y = {y_1, y_2,..., y_N}를 구합니다. y_i은 0 혹은 1의 값을 가지며, 1이면 extractive summary에 포함됩니다. Extractive summary는 M <= N인 summary S*={s*_1, s*_2,... , s*_M}을 만드는데 그 목표가 있습니다.
- Graph Construction
- Node
- Named entity / word / sentence 세 종류의 노드가 있습니다.
- Semantic sparsity를 줄이기 위하여, Named entity의 text span을 anonymized token으로 대체합니다. 예를 들어 Mike -> [Person_A], 20220330 -> [Date_A]와 같이 대체합니다. Word node는 word-level information을 표현합니다. DivGraphPointer[1] 에서는 같은 word는 하나의 node로 aggregate 하였는데, HAHSum에서는 같은 단어라도 다른 context에서 사용되는 것을 고려하여 각기 다른 node로 graph를 구성합니다. Sentence node는 하나의 sentence에 대응되고, 한 문장의 global information을 표현합니다.
- Edge
- 'Next': 하나의 문장 안에 연속적인 named entity와 word 는 방향성이 있는 'Next' edge로 연결합니다.
- 'In': named entity나 word를 그 문장이 속해 있는 sentence node에 directed 'In' edge로 연결합니다.
- 'Same': 두 named entity가 같다면 undirected 'Same' edge로 연결합니다.
- 'Similary': 두 문장들 간의 trigram overlapping이 있다면 'Similar' edge로 연결합니다.
- Graph 종류
- Graph는 adjacency matrix A로 표현될 수 있습니다. HAHSum은 word-level, word-sentence, 그리고 sentence-level sub graph가 있기 때문에, 각 subgraph를 표현하는 adjacency matrix인 A_word, A_word-sent, A_sent를 정의합니다.
- 1. A_word는 entity와 word node가 있고, Next 와 Same edge가 있습니다.
2. A_word-sent는 word, entity, sentence node들과 In edge가 있습니다.
3. A_sent는 sentence node와 similar edge가 있습니다. - Word-level부터 sentence-level graph까지 information을 propagating 하면서, sentence representation와 문장들 간 redundancy를 모델링할 수 있습니다.
- Graph Attention Network
GAT는 각 node의 주변 node들의 정보들을 aggregating하여 각 node의 hidden representation을 배웁니다. 이때 attention coefficients를 사용합니다 (식 1).

x_i, x_j는 각 node를 표현하는 dx1 vector이고, W는 dxd 크기의 weight matrix입니다. W와 각 node vector 간 행렬 곱을 한 후에, 그 결과를 concatenation ( || ) 하여 2d x 1 vector를 만듭니다. a는 1 x 2d 크기의 attentional weight vector이고, concatenation 결과와 행렬 곱을 하여 scala를 만들고 이를 LeadkReLU activation function에 넣어 i와 j 간 attention coefficient를 계산합니다.
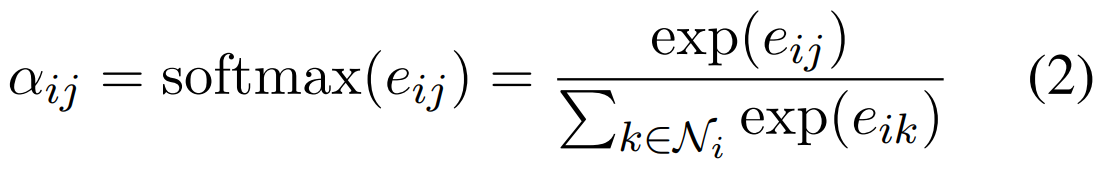
Attention coefficient를 normalize 하기 위하여 softmax 합니다 (식 2).

Normalization 된 attention coefficient과 각 node의 neighbor node들과 linear combination을 합니다. 그 이후 원래 node vector와 더하여 주변 node의 feature를 attention을 활용하여 합쳐주게 됩니다. W'는 x_i와 x_i 주변 neighbors을 구분하기 위해 사용됩니다.
- Message Passing
그림 1과 같이 HAHSum은 ALBERT Encoder, Abstract Layer, Redundancy Layer 그리고 Output Layer로 구성됩니다. 앞으로는 어떻게 이 layer들을 걸쳐 information이 propagation 되는지 설명합니다.
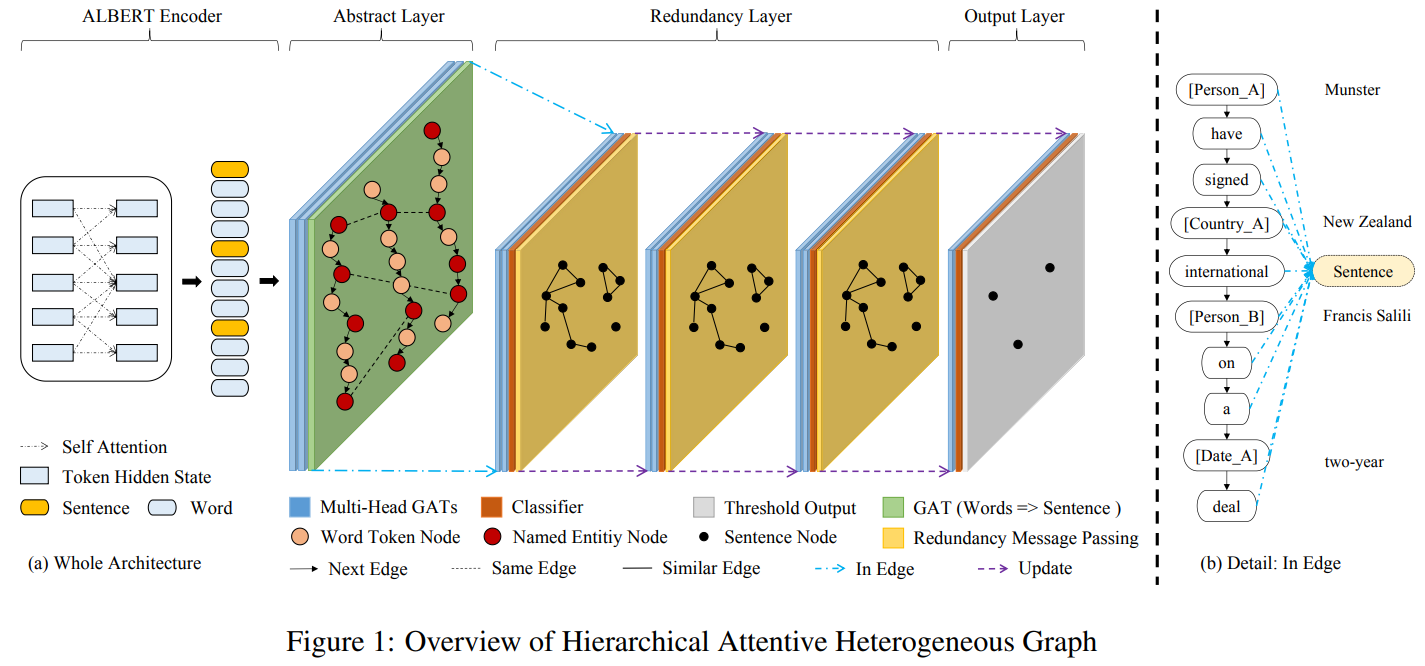
1. ALBERT encoder의 출력은 word와 sentence에 대한 hidden state입니다. 같은 word에 대하여 여러 hidden states이 있는 경우 average pooling을 합니다.
2. Abstract Layer는 3개의 GAT layer로 구성됩니다. 두 layer들은 word-level graph를 위한 것들(식 4)이고, 나머지 하나는 word-sentence 변환을 위한 것(식 5)입니다. h는 ALBERT의 출력, A는 adjacency matrix를 의미합니다. BERT와 Abstract Layer를 거쳐 전반적인 context representation들의 salience를 modeling 합니다.


3. Redundancy Layer는 message passing을 활용하여 반복적으로 sentence representation을 update 하여 redundancy를 modeling 합니다. Redundancy layer는 두 개의 1) GAT layer, 2) classifier, 그리고 3) redundancy를 줄이는 layer로 구성됩니다.
1) GAT Layer
먼저 GAT layer의 첫 번째 입력으로 이전 layer의 sentence representation을 받습니다.

2) Classifier
GAT layer의 출력인 sentence embedding(h_i)을 multihead-attention과 layer normalization, feed-forward network로 구성된 classifier에 입력하여 각 sentence가 extractive summarization에 포함할 확률을 출력합니다.

L개의 classifier에 대하여 동시에 train 합니다. 각 binary cross entropy를 layer가 뒤로 갈수록 더 가중치를 주는 형태로 loss function을 구성합니다.
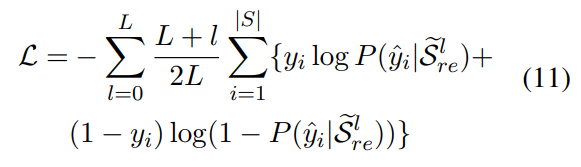
3) Reducing redundancy
Node i의 neighbors에 속하는 node들의 embedding과 extractive summary에 속한 probability를 곱한 weighted summation을 합니다. 그리고 node i의 embedding에 neighborhood information을 빼서 redundancy를 update 합니다. 얼마나 뺄 것인지는 W_c, W_r로 조절합니다.

Experiments
실험 결과 다른 model 대비 우월한 성능을 보였고, CNN/DM은 특히 SOTA를 달성하였습니다.

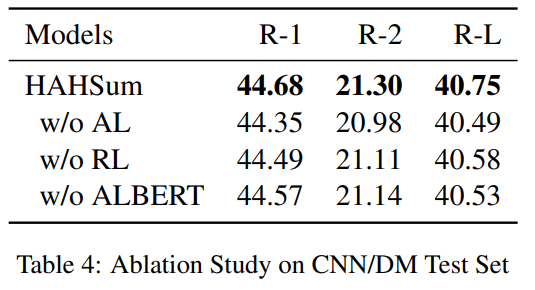
Abstract Layer와 Redundancy Layer, Pretrained ALBERT의 성능을 평가하기 위하여 ablation study를 진행하였습니다. 각 요소가 ROUGE 성능에 기여함을 알 수 있습니다.
References
[1] Zhiqing Sun, Jian Tang, Pan Du, Zhi-Hong Deng, and Jian-Yun Nie. 2019. Divgraphpointer: A graph pointer network for extracting diverse keyphrases. In International ACM SIGIR Conference on Research and Development in Information Retrieval.