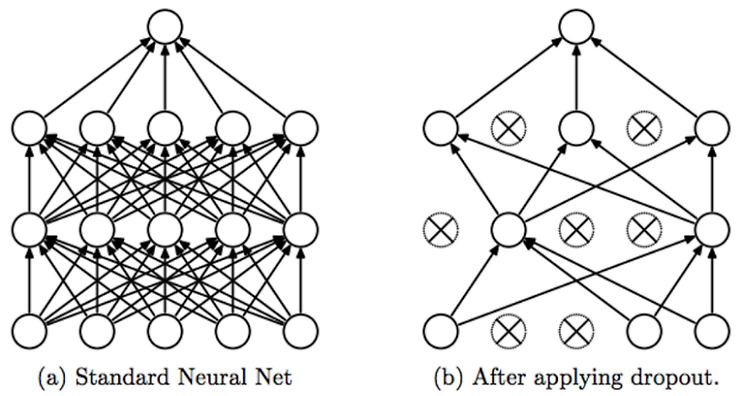
Regularization for neural networks Regularization은 머신러닝에서 굉장히 중요한 주제입니다. 먼저 간단히 선형 회귀에서 활용되는 Regularization 기법에 대해서, 그리고 Neural Network에서 사용되는 기법들에 대해서 적어보려고 합니다. 서울대학교 이준석 교수님의 ‘시각적 이해를 위한 기계학습’ 와 위키피디아를 참고했음을 밝힙니다. 우리가 어떤 데이터에 대하여 모델을 fitting 시키는데, general한 trend에 fitting 시킬수록 좋습니다. Overfitting은 학습 데이터의 노이즈가 있을 때, 이 노이즈까지 fitting하는 것을 말합니다. 만약 모델이 불필요하게 복잡하다면 Overfitting의 증거일 수 있습니다. 이것을 방지하기 ..