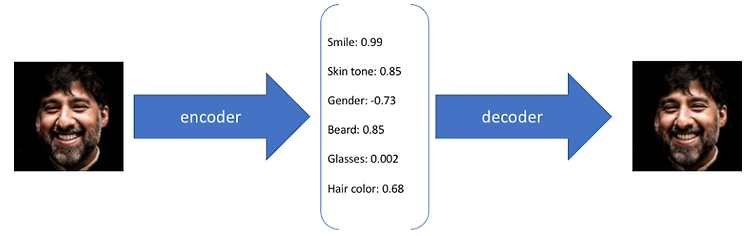
Autoencoding beyond pixels using a learned similarity metric 논문은 VAE-GAN 모델로 더 유명합니다. VAE와 GAN을 결합한 첫 번째 Architecture이고, VAE의 Pixel level reconstruction error를 Feature level error로 개선한 모델입니다. AAE는 KL divergence loss를 개선한 것과 차이가 있습니다. VAE-GAN 모델은 VAE와 GAN을 결합하여 VAE의 reconstruction을 element-wise error 대신 feature-wise error로 대체하여 이미지가 약간 translation 되어도 invariance 되도록 합니다. CelebA 데이터에 VAE/GAN을 적용해본..