Going deeper with convolutions (GoogLeNet)

Google에서 발표한 GoogleNet에 대한 리뷰입니다. 2014년 ImageNet에서 굉장히 좋은 성능을 얻었습니다. Inception 영화에서 영감을 얻었다고 하여 Architecture의 코드 네임을 Inception으로 하였다고 합니다. 이 논문 이후 Inception을 개선한 Inception v2, 3, 4 등이 발표되었습니다.
1. Introduction
Convolutional networks의 발전에 따라 image recognition과 object detection 품질이 드라마틱하게 증가하고 있습니다. 하드웨어가 좋아지고 데이터 셋이 많아졌기도 하지만, 주로 네트워크 구조를 개선한 새로운 아이디어와 알고리즘 덕분입니다. GoogLeNet도 ILSVRC 2014도 데이터는 변경되지 않았는데 이전 모델들의 성능을 뛰어넘었습니다.
또한 모바일과 임베디드 컴퓨팅이 발전함에 따라 알고리즘의 효율(파워 그리고 메모리 사용량 등)이 중요해지고 있습니다. 그 점에서 GoogLeNet의 효율은 좋은 편이라 합니다 (아마 1 X 1 Convolution으로 파라미터 수를 줄인 부분을 강조하고 싶었던 것이 아닐까 생각됩니다).
본 논문의 제목에 사용된 "Deep"은 두 가지 의미가 있습니다. 네트워크가 깊어진다는 의미와 Inception module를 사용했다는 것 입니다.

2. Related Work
LeNet-5에서부터 시작해서, CNN은 그 이름처럼 convolution layer들을 쌓고 그 뒤에 FC layer들을 쌓는 구조로 발전해오고 있습니다. 최근 (2014년이니 '최근'은 아니지만 요즘도 유효한 듯 합니다) 트렌드는 layer 수를 늘리고 크기를 키우되, overfitting을 피하기 위하여 dropout을 사용합니다.
Max-pooling layer가 공간적인 정보를 잃어버린다는 걱정에도 불구하고 CNN은 localization과 object detection 등 여러 테스크에서 좋은 성능을 보이고 있습니다. Serrer et al. 은 Inception module처럼 각기 다른 Gabor filter를 적용하여 다양한 scale을 다루려는 시도를 했었습니다 (Robust object recognition with cortex-like mechanisms)만, layer 수가 2개 밖에 없었죠.

Network-in-Network (Lin et al. 2013 CoRR)에서는 Filter 대신에 non-linearity를 넣기 위하여 Multi Layer Perceptron(MLP)를 활용하였습니다. 이 MLP는 1 X 1 Convolutional layer에 ReLU과 같은 Activation이 붙여진 것으로 볼 수 있습니다. GoogleNet에서는 Parameter 수를 줄여서 computational bottleneck을 피하기 위하여 이 1 X 1 Convolution을 많이 활용하고 있습니다. 이를 통해 큰 performance penalty 없이 네트워크의 depth와 width(Inception module)을 키우는 것이 가능했습니다.


3. Motivation and High Level Considerations
Deep neural network의 성능을 높이는 직접적인 방법은 그 크기(depth, width)를 늘리는 것 입니다. 이 간단한 방법에는 두 가지 단점이 있습니다. 학습할 파라미터 수가 증가하여 Overfitting이 될 위험이 있다는 것과 Computational 자원이 더 많이 필요하다는 것 입니다. 이는 sparsely connected architecture로 해결 가능하다고 합니다.

이런 sparsely connected architecture는 Biological system을 모방하는 것 입니다. 고양이가 특정 패턴을 볼 때 뉴런이 반응하는데요, 실제로 각 패턴에 반응하는 뉴런의 집합은 전체 뉴런에 비해 극히 일부이므로 sparse하게 동작하는 것으로 볼 수 있습니다.

또한 Arora의 연구(https://arxiv.org/abs/1310.6343)에서 비록 여러 조건들이 필요하지만 sparse deep neural network은 상관성이 높은 뉴런들끼리 clustering하게 되면 optimal network가 된다고 합니다.
Sparse data structured의 numerical calculation이 비효율적입니다만 sparse matrix 계산은 더 dense한 submatrix로 clsutering하게 되면 계산 속도가 더 빨라진다고 합니다.
Inception architecture는 Arora의 연구에서 말한 sparse structure에 대한 근사화를 포함해, dense하면서도 쉽게 사용할 수 있도록 정교하게 설계된 Network construction의 사례 연구로 시작되었습니다.
4. Architectural Details
Inception architecture의 main idea는 CNN에서의 optimal local sparse structure를 dense components로 근사하는 것 입니다. 우리는 이미지의 채널들 위에 같은 위치의 존재하는 픽셀들은 서로 상관성이 존재함을 알고 있습니다. 이는 1 X 1 convoluion을 적용하여 dense하게 만들 수 있습니다. 하나의 픽셀 보다 조금 더 넓은 영역 간 상관성은 3 X 3 convolution이나 5 X 5 convolution와 같은 더 큰 filter size를 적용하면 됩니다.
Inception module에서는 patch-alignment issue(Filter size가 짝수일 경우에는 filter의 중심을 어디로 해야 할지 정해야하는 문제)를 피하기 위해 1 X 1, 3 X 3, 5 X 5 Filter를 활용합니다. 또한 최근 SOTA ConvNet에서 Pooling 을 사용하기 때문에, 추가적인 이점이 있을 것으로 생각하여 활용합니다.
아래는 3가지의 convolution들과 max pooling의 출력을 concatenation하는 Inception module에 대한 그림입니다. 이런 디자인의 실용적인 측면은, 이전 레이어에서 여러 다른 scale의 feature들을 뽑아 활용한다는 점 입니다.

Naive Inception Module은 계산량이 많이 Computationally 비쌉니다. 특히 3 X 3, 5 X 5 Conv의 계산량이 많습니다.

이를 개선하기 위해 1 X 1 Conv를 활용하여 dimensen reduction을 수행할 수 있습니다.

1 X 1 conv를 활용하여 차원을 줄이고 연산량을 감소 시킨 버전입니다.

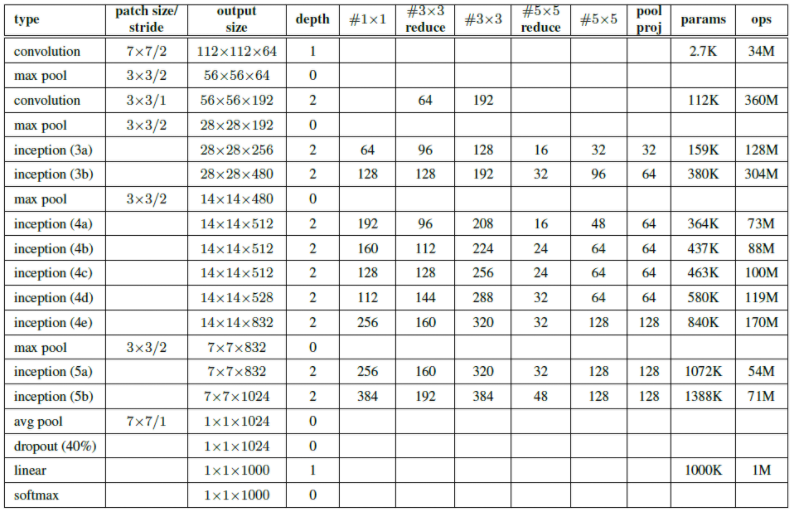
5. GoogLeNet: Full Architecture

GoogLeNet의 Architecture는 stem networkds + inception module + classifier로 구성됩니다.
깊어서 gradient가 vanishing되니, inception module의 3층, 6층 별로 보조 분류기(Auxiliary classifier)를 추가하여 gradients를 전파하여 학습될 수 있도록 하였습니다. 물론 실제 inference할 때는 사용하지 않습니다. 저자들은 보조 분류기의 추가가 regularization 효과와 함께 vanishing gradient problem를 해결해주는 것으로 생각하는데요. 향후 Inception의 개선된 버전에서는 이 Auxiliary loss가 불필요하다고 하며 뺀다고 합니다.
6. Training Methodology
사용한 optimizer는 SGD + 0.9 Momentum를 사용하였습니다.
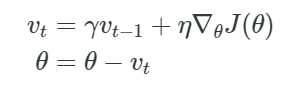
데이터 Augmentation: Image crops / Resize + Interpolation ..


7. ILSVRC 2014 Classification Challenge Results

References
1. arxiv.org/abs/1409.4842
2. sike6054.github.io/blog/paper/second-post/
3. www.youtube.com/watch?v=_XF7N6rp9Jw
4. www.cs.colostate.edu/~dwhite54/InceptionNetworkOverview.pdf
5. cs231n.stanford.edu/slides/2020/lecture_9.pdf
'Machine Learning, Deep Learning' 카테고리의 다른 글
| Data augmentation: color jitter (0) | 2021.04.18 |
|---|---|
| Variational autoencoder (1) | 2021.04.16 |
| [Paper review] Very Deep Convolutional Networks For Large-Scale Image Recognition (0) | 2021.04.05 |
| Transfer learning (0) | 2021.04.05 |
| Optimization beyond SGD (0) | 2021.04.03 |