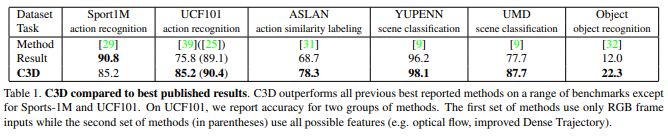
Learning-Spatiotemporal-Features-with-3D-Convolutional-Networks-C3D Introduction Video analysis 인터넷에 비디오 데이터 양이 폭발적으로 많아지고 있음. 비디오 분석에는 Action recognition, abnormal event detection 등 다양한 문제들이 있고 연구되고 있는데, 이를 범용적으로 다룰 수 있는 일반적인 모델이 없음. 비디오 descriptor(비디오에서 visual features를 추출해주는 모델)는 네가지 성질이 있어야 함. generic: 비디오는 다양한 타입의 데이터가 있기 때문에. compact: 데이터의 크기가 커서, scalable하려면 compact해야 함. efficient: 수천개의 비..